

Distributed computing: calcolo distribuito per infrastrutture digitali efficienti

Il distributed computing (in italiano “calcolo distribuito”) è ormai parte integrante nell’ambito della vita quotidiana e lavorativa. Chi naviga in Internet ed effettua una ricerca su Google utilizza proprio il distributed computing. Le architetture di sistema distribuite caratterizzano anche molte attività d’impresa e forniscono a un gran numero di prestazioni e servizi, sufficienti capacità di calcolo ed elaborazione. Vi spiegheremo di seguito come funziona questa procedura e raffigureremo le architetture di sistema utilizzate e gli ambiti di impiego. Verranno anche trattati i vantaggi del calcolo distribuito.
Cos’è il distributed computing?
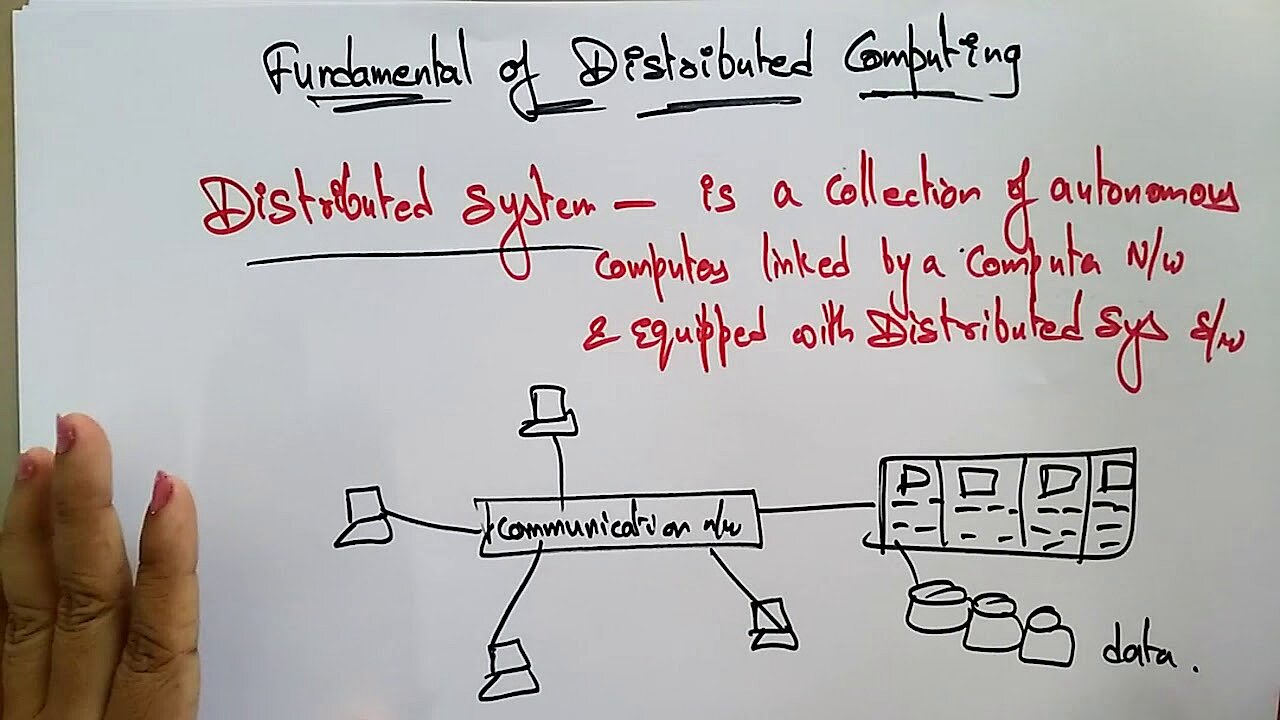
Il termine “distributed computing” definisce un’infrastruttura digitale in cui un cluster risolve dei compiti di calcolo. Nonostante la distanza fisica, i computer lavorano autonomamente e in modo strettamente interconnesso in un processo di suddivisione dei compiti. Per la procedura è secondario il tipo di server utilizzato, oltre a computer particolarmente performanti e postazioni di lavoro di tipo professionale, si possono collegare anche minicomputer e computer desktop di utenti privati.
Visto che l’hardware condiviso non può avere una memoria comune a causa della separazione fisica, i computer interessati si scambiano messaggi e dati come risultati di calcolo tramite una rete. La comunicazione tra computer avviene localmente per mezzo di Intranet (ad esempio in un centro di calcolo) o a livello interregionale o globale via Internet. La trasmissione dei messaggi è effettuata tramite protocolli Internet come TCP/IP e UDP.
All’insegna del principio di trasparenza, il distributed computing aspira a mostrarsi esternamente come un’unità funzionale e a semplificare il più possibile il controllo della parte tecnica. Gli utenti che ad esempio effettuano la ricerca di un prodotto nella banca dati di un negozio online, considerano l’esperienza d’acquisto come un processo unico e non devono preoccuparsi dell’architettura di sistema modulare dell’infrastruttura utilizzata.
Infine il distributed computing è anche una combinazione di distribuzione dei compiti e interazione coordinata. Lo scopo è quello di rendere il più efficiente possibile la gestione dei compiti e di trovare soluzioni flessibili e pratiche.
Come funziona il distributed computing?
Il punto di partenza di un calcolo nel distributed computing è una particolare strategia per la risoluzione dei problemi. Un singolo problema viene suddiviso e ciascun sotto-settore viene elaborato da un’unità di calcolo. Le applicazioni distribuite (Distributed Applications), che girano su tutte le macchine del cluster, si occupano dell’attuazione operativa.
Le applicazioni distribuite si servono spesso di un’architettura client-server. Client e server operano tramite suddivisione del lavoro e coprono con i software installati determinate funzioni di applicazione. La ricerca di un prodotto avviene come segue: il client funge da istanza di inserimento e interfaccia utente, che accoglie la richiesta dell’utente e la predispone di modo che venga inoltrata a un server. Il server remoto si fa carico della parte principale della funzione di ricerca ed effettua la ricerca in una banca dati. Il risultato della ricerca viene preparato lato server per essere trasportato nuovamente al client e comunicato allo stesso per mezzo della rete. Alla fine si ha l’output del risultato sul display dell’utente.
Nel processo distribuito vengono più spesso inclusi dei Middleware-Services. Il middleware, come speciale strato software, definisce lo schema (logico) di interazione tra partner e garantisce nel sistema distribuito la conciliazione e un’integrazione ottimale. Così vengono messi a disposizione interfaccia e servizi che servono ad eliminare i gap tra diverse applicazioni, consentendo e monitorando la comunicazione tra questi (per esempio tramite controller di comunicazione). Per lo svolgimento operativo, il middleware mette ad esempio a disposizione con il Remote Procedure Call (RPC) un comprovato sistema di comunicazione tra processi per dispositivi diversi, che viene spesso utilizzato nelle architetture client-server per trovare prodotti nelle ricerche nelle banche dati.
Questa funzione di integrazione, che lavora secondo il principio della trasparenza, può essere interpretata anche come funzione di traduzione. Sistemi applicativi e piattaforme eterogenei dal punto di vista tecnico, che normalmente non potrebbero comunicare tra loro, parlano per così dire la stessa lingua e lavorano assieme in maniera produttiva grazie al middleware. Il middleware, oltre che per l’interazione tra dispositivi e piattaforme, si occupa anche di altri compiti, come la gestione dei dati. Inoltre regola l’accesso delle applicazioni distribuite alle funzioni e ai processi dei sistemi operativi, che sono disponibili localmente sui computer collegati.


 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Quali tipi di distributed computing esistono?
Il distributed computing è un fenomeno sfaccettato con infrastrutture in parte anche molto diverse. Risulta quindi difficile determinare tutte le varianti del distributed computing. A questa area dell’informatica vengono però più frequentemente attribuiti tre sotto-aree o sotto-settori:
- Cloud Computing
- Grid Computing
- Cluster Computing
Nel Cloud Computing si utilizza il calcolo distribuito per mettere a disposizione dei clienti infrastrutture e piattaforme altamente scalabili e vantaggiose dal punto di vista economico. I fornitori in cloud provvedono per lo più fornendo le loro capacità sotto forma di servizi hostati. Nella pratica si sono affermati diversi modelli:
- Software as a Service (SaaS): con il servizio SaaS il cliente utilizza le applicazioni di un fornitore cloud e le relative infrastrutture (come server, memoria online, capacità di calcolo). L’accesso alle applicazioni è possibile con diversi dispositivi tramite un cosiddetto “Thin Client Interface” (per esempio una web app basata su browser). La gestione e l’amministrazione delle infrastrutture dislocate viene assunta dal fornitore del cloud.
- Platform as a Service (PaaS): nel caso del servizio PaaS viene messo a disposizione un ambiente basato su cloud, come per lo sviluppo di applicazioni web. Il cliente assume il controllo delle applicazioni messe a disposizione e può configurare delle impostazioni ad hoc per l’utente, il gestore del cloud si occupa dell’infrastruttura tecnica per il distributed computing.
- Infrastructure as a Service (IaaS): nel caso del servizio IaaS viene messa a disposizione del provider in cloud un’infrastruttura tecnica, alla quale gli utenti possono avere accesso tramite reti private o pubbliche. Fanno ad esempio parte dei componenti dell’infrastruttura resi disponibili: server, capacità di calcolo e di rete, dispositivi di comunicazione come router, switch o firewell, spazio di salvataggio e sistemi per l’archiviazione e backup dati. Il cliente, dal canto suo, assume il controllo sui sistemi operativi e sulle applicazioni rese accessibili.
Il grid computing si orienta verso l’idea di un supercomputer con un’enorme capacità di calcolo. Le attività di calcolo sono però svolte non da una, bensì da molte istanze. I server e i PC possono farsi carico in modo indipendente l’uno dall’altro di diversi compiti. I grid computing può avere accesso in maniera molto flessibile alle risorse per la gestione dei compiti. Solitamente i partecipanti a un progetto comune mettono a disposizione determinate capacità di calcolo la sera, quando l’infrastruttura tecnica non è molto sfruttata.
Un vantaggio è dato dal fatto che possono essere utilizzati sistemi molto performanti in maniera rapida e, a seconda della necessità di potenza di calcolo, è possibile scalarli. Per aumentare la potenza non è necessario sostituire o potenziare un costoso supercomputer con un oneroso modello più all'avanguardia.
Visto che il grid computing è in grado di creare un supercomputer virtuale da un singolo computer accoppiato a un cluster, è anche specializzato in problemi che richiedono un elevato volume di calcolo. Questa procedura viene spesso utilizzata per progetti scientifici ambiziosi o per decodificare codici crittografici.
Il cluster computing non è facilmente distinguibile dal grid computing. Il termine viene utilizzato in maniera più generale e si riferisce a tutte le forme che uniscono il singolo computer e le sue capacità di calcolo a un cluster (in italiano “grappolo”, “fascio”). Così abbiamo ad esempio cluster di server, cluster per big data e ambiente cloud, cluster di banche dati e cluster di applicazioni. Inoltre i cluster sono maggiormente inclusi nell’High-Performance-Computing, che mira a risolvere problemi complessi.
È anche possibile definire diversi tipi di distributed computing, quando si utilizzano architetture di sistema e modelli d’iterazione di un’infrastruttura condivisa. Date le complesse architetture di sistema del distributed computing si parla spesso anche di distributed systems (in ita. “sistemi distribuiti”).
Tra i più diffusi modelli di architetture del distributed computing troviamo:
- modello client-server
- modello peer-to-peer
- modelli a strati (architetture multi-tier)
- architettura orientata ai servizi (in ingl. service-oriented architecture, SOA)
Il modello client-server è un semplice modello di interazione e comunicazione nel distributed computing. Un server riceve una richiesta da un client, esegue le procedure di elaborazione necessarie e rimanda allo stesso una risposta (messaggio, dati, risultati di calcolo).
Un’architettura peer-to-peer organizza l’interazione e la comunicazione del distributed computing secondo punti di vista decentrati. Tutti i computer (chiamati anche nodes, in italiano “nodi”) hanno gli stessi diritti e assumono gli stessi compiti e funzioni all’interno della rete. Ogni computer può quindi fungere sia da client che da server. Un esempio di architettura peer-to-peer è la blockchain delle criptovalute.
Nella concezione di un’architettura a strati i singoli aspetti di un sistema software vengono suddivisi in più livelli (ingl. tier, layer), così da aumentare l’efficienza e la flessibilità del distributed computing. Questa architettura di sistema può essere organizzata come architettura a due livelli (two-tier), a tre livelli (three-tier) o a N livelli (N-tier) e viene spesso utilizzata dalle agenzie pubblicitarie.


Un’architettura orientata al servizio (SOA) mette al centro i servizi e si rivolge in maniera personalizzata alle esigenze e alle procedure di un’azienda. Così i singoli servizi si uniscono in un processo aziendale pensato ad hoc. Ad esempio l’intero processo di un “ordine online” può essere rappresentato in un SOA, che prevede i servizi “accettazione ordine”, “verifica credito” e “invio fattura”. Le componenti tecniche (server, banca dati, ecc.), fungono da strumenti ausiliari, ma non sono in primo piano. In questo progetto di distributed computing ad avere la priorità sono l’intelligente raggruppamento, collaborazione e organizzazione dei servizi, prestando attenzione a come svolgere nel modo più efficiente e senza intoppi i processi aziendali.
In un’architettura orientata ai servizi si attribuisce particolare importanza a interfaccia ben definite, che uniscano i componenti in maniera operativa e aumentino l’efficienza. Quest’ultima trae vantaggio anche dalla flessibilità del sistema, visto che i servizi possono essere applicati in maniera variabile a più contesti e riutilizzati nei processi aziendali. Le architetture orientate ai servizi, che puntano sul distributed computing, si basano spesso su servizi web. Vengono ad esempio realizzati su piattaforme condivise come CORBA, MQSeries e J2EE.
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
I vantaggi del distributed computing
Il distributed computing presenta molti vantaggi. Le aziende possono realizzare un’infrastruttura performante e accessibile che, al posto di grandi computer estremamente costosi (mainframes), utilizza computer comunemente in commercio con microprocessori. I grandi cluster possono addirittura superare le capacità di singoli supercomputer e risolvere complesse attività di calcolo dell’High-Performance-Computing.
Dato che le architetture di sistema del distributed computing sono basate su molte componenti, a volte ridondanti, è facile compensare la perdita di singole unità (maggior sicurezza in caso di malfunzionamento). Grazie all’elevata suddivisione dei compiti, i processi possono essere dislocati e il carico di calcolo suddiviso (distribuzione dei carichi).
Molte soluzioni del distributed computing puntano ad una maggior flessibilità, che solitamente accresce anche efficienza e redditività. Per trovare una soluzione a determinati problemi possono essere incluse piattaforme specializzate come server per banche dati. Per esempio, tramite le architetture SOA in ambito aziendale si creano delle soluzioni personalizzate, che ottimizzano ad hoc determinati i processi aziendali. I gestori possono offrire capacità di calcolo e infrastrutture a livello internazionale, consentendo così anche il lavoro in cloud. In questo modo è possibile far fronte alle esigenze dei clienti con offerte scaglionate e corrispondenti ai loro bisogni.
Uno degli elementi che contribuiscono alla flessibilità del distributed computing è il fatto che permette di sfruttare anche capacità temporaneamente inutilizzate per progetti particolarmente ambiziosi. Gli utenti sono in grado di contare sulla flessibilità anche nell’acquisto degli hardware, visto che non sono legati ad un singolo produttore.
Un notevole vantaggio è dato dalla scalabilità. Alle aziende viene messa a disposizione una scalabilità a breve termine e rapida o, in caso di continua crescita di organico, l’adeguamento progressivo delle prestazioni di calcolo necessarie per le proprie esigenze. Nel caso in cui per la scalabilità si punti su hardware propri, il parco dispositivi può essere continuamente ampliato in step economicamente accessibili.
Nonostante i notevoli vantaggi, il distributed computing presenta anche alcuni svantaggi, un notevole impegno in termini di implementazione e manutenzione nel caso di architetture di sistema complesse. Inoltre i problemi di timing e di sincronizzazione devono essere superati tra istanze distribuite. Per quanto riguarda la sicurezza in caso di malfunzionamento, l’approccio decentralizzato è vantaggioso rispetto ad una singola istanza di elaborazione. Però le procedure connesse al distributed computing comportano anche problemi di sicurezza, come lo scambio dati tramite reti aperte e la vulnerabilità a sabotaggi e hackeraggi. Le infrastrutture distribuite sono in generale più soggette all’errore, visto che a livello di hardware e di software ci sono più interfacce e potenziali fonti di problemi. La diagnosi dei problemi e degli errori è inoltre resa più difficile dalla complessità infrastrutturale.
Dove viene utilizzato il distributed computing?
Il distributed computing è diventato una tecnologia di base essenziale per la digitalizzazione della vita quotidiana e lavorativa. Internet e i servizi che questo offre sarebbero impensabili senza le architetture client-server e i sistemi distribuiti. Il distributed computing entra in gioco ad ogni ricerca effettuata con Google, quando istanze di fornitura in tutto il mondo generano in stretta collaborazione un adeguato risultato di ricerca. Anche Google Maps e Google Earth per i loro servizi si servono del distributed computing.
Anche sistemi mail e per le conferenze, sistemi di prenotazione di compagnie aeree e di catene di hotel, biblioteche e sistemi di navigazione utilizzano le procedure e le architetture del calcolo condiviso. I processi di automazione così come i sistemi di pianificazione, produzione e progettazione nel mondo del lavoro sono i campi di applicazione d’elezione di questa tecnologia. Le reti sociali, i sistemi mobile, l’onlinebanking e l’onlinegaming (sistemi multiplayer) utilizzano efficienti distributed systems.
Altri campi di applicazione del distributed computing sono le piattaforme di e-learning, l’intelligenza artificiale e l’e-commerce. Gli acquisti e gli ordini negli shop online vengono solitamente supportati da sistemi distribuiti. In meteorologia i sistemi di rilevamento e monitoraggio nella previsione delle catastrofi puntano sulle capacità di calcolo di sistemi distribuiti. Molte applicazioni digitali oggigiorno si basano su banche dati distribuite.
Progetti di ricerca che richiedono elevate capacità di calcolo, per i quali prima servivano costosi supercomputer (ad esempio computer Cray), possono ora essere realizzati con i sistemi distribuiti. Il progetto Volunteer-Computing Seti@home è stato lo standard di riferimento nell’ambito del calcolo condiviso dal 1999 al 2020. Un numero indefinito di computer domestici di utenti privati hanno valutato i dati del radiotelescopio Arecibo che si trova a Puerto Rico, e hanno così aiutato l’università di Berkeley nella ricerca della vita al di fuori del nostro pianeta.
Una particolarità è stata quella dell’approccio efficiente nell’uso delle risorse: il software di valutazione lavorava solamente nelle fasi in cui i computer degli utenti non erano altrimenti occupati. Dopo l’analisi dei segnali, i risultati tornavano alla centrale di Berkeley. Esistono progetti comparabili in tutto il mondo anche in altre università e istituti.
Le basi del distributed computing vengono rappresentate in modo semplice tramite vari video esplicativi sul canale YouTube di Education 4u.