
Database: a cosa servono e quali tipi ci sono

Database: a cosa servono e quali tipi ci sono
Un database raccoglie dati e li collega in un’unità logica. I singoli dati sono forniti con metadescrizioni e le informazioni necessarie per la loro elaborazione. I database sono estremamente utili per la gestione dei dati e semplificare la ricerca di informazioni specifiche. Inoltre in molti database si possono stabilire tramite i diritti di accesso quali persone o programmi possano accedere a quali dati. Si occupano anche di rappresentare i contenuti in modo chiaro e consono ai bisogni.
I sistemi di database differiscono tra loro a livello concettuale e hanno di conseguenza pregi e difetti peculiari. Tutti si basano però su una suddivisione in database e sistema di gestione del database. Il database indica l’insieme di tutti i dati che devono essere ordinati (insieme indicato anche come “base di dati”). Il sistema di gestione del database è responsabile appunto per la gestione e stabilisce la struttura, l’ordine, i diritti di accesso, le dipendenze etc. Per fare questo spesso utilizza una lingua di database appositamente definita e un appropriato modello di database che specifica l’architettura del sistema di database.
I database sono sistemi di gestione dei dati elettronici logicamente strutturati, che con l’aiuto di un sistema di gestione del database regolano appartenenze e diritti di accesso e archiviano le informazioni riguardo alla base di dati contenuta. La maggior parte dei database si possono aprire, modificare e leggere soltanto con particolari applicazioni per database.
A cosa servono i database?
Già negli anni 60 era stato elaborato il concetto di database elettronico come livello separato di software tra il sistema operativo e il programma dell’applicazione, in grado di strutturare l’elaborazione dei dati elettronici in modo efficiente. Del resto si è trattato di uno sviluppo naturale: il lavoro manuale file per file, la supervisione e la suddivisione dei diritti di accesso rendevano il lavoro troppo macchinoso, rendendo l’elaborazione elettronica dei dati un alleggerimento concreto del lavoro. L’idea dei sistemi di database elettronici è stata una delle innovazioni più importanti nello sviluppo del computer.
Inizialmente sono stati sviluppati modelli di database gerarchici e di rete, che però presto si sono dimostrati troppo semplici e tecnicamente limitati. Negli anni 70 grazie a IBM ci fu un notevole passo avanti con lo sviluppo del modello di database relazionale, che si diffuse rapidamente nel mondo del lavoro. I prodotti di maggior successo di questo periodo erano il linguaggio di database SQL di Oracle e i prodotti successivi di IBM, SQL/DS e DB2.
Fino agli anni 2000 nel mercato dei software per i database dominavano principalmente i fornitori di grande fama, fino a quando alcuni progetti open source portarono una ventata di aria fresca. I più popolari sistemi liberamente accessibili sono MySQL e PostgreSQL. La tendenza verso i sistemi NoSQL dal 2001 ha continuato a sfidare la tradizione dei sistemi di database relazionali dei produttori.
Oggi i sistemi di database sono diventati irrinunciabili per molti ambiti di applicazioni. Ogni software aziendale si basa su database potenti che rendono disponibili una vasta gamma di opzioni e strumenti per gli amministratori di sistema. Inoltre il tema della sicurezza dei dati nei sistemi di database è diventato sempre più importante: infatti nei database elettronici vengono archiviate e crittografate password, informazioni personali, nonché valute elettroniche.
Il moderno sistema finanziario si può ad esempio immaginare come un grande network di database. La maggior parte delle somme in denaro esistono come unità di informazione elettroniche e la tutela di queste informazioni grazie a database sicuri è un compito essenziale degli istituti finanziari. Un ulteriore motivo che ci fa comprendere l’importanza dei database per la nostra civiltà.
Funzioni e requisiti di un sistema di gestione dei database (DBMS)
Un termine ampiamente utilizzato che descrive le funzioni e i requisiti per le transazioni del sistema di gestione dei database è ACID (conosciuto anche come AKID), un acronimo per atomicity, consistency, isolation e durability (atomicità, coerenza, isolamento e durabilità). Le sottosezioni di ACID a loro volta coprono i requisiti più importanti per un DBMS:
- L’atomicità indica la proprietà “tutto o niente” del DBMS, nel senso che solo le richieste valide vengono eseguite nell’ordine stabilito, garantendo la correttezza dell’intera transazione.
- La coerenza richiede che le transazioni riuscite lascino un database stabile, che a sua volta richiede una revisione costante di tutte le transazioni.
- Per isolamento si indica il requisito che le transazioni non si ostacolino l’un l’altra, il che è garantito da specifiche funzioni di blocco.
- Per durabilità si intende che tutti i dati sono memorizzati in modo permanente nel DBMS, anche dopo aver completato una transazione corretta. Questo vale anche o soprattutto in caso di errori di sistema o guasti del DBMS. Per garantire la durabilità sono essenziali ad esempio i registri delle transazioni, che archiviano tutti i processi del DBMS.
Di seguito trovate un breve prospetto delle funzioni e dei requisiti di un sistema di gestione di database che superano il modello ACID.
| Funzione/requisito | Spiegazione |
| Archiviazione dei dati | I database archiviano testi, documenti, password e altre informazioni che possono essere richiamati con le query. |
| Revisione dei dati | La maggior parte dei database consentono, a seconda dei diritti di accesso, di elaborare direttamente le informazioni archiviate. |
| Cancellazione dei dati | I dati contenuti nei database si possono cancellare completamente. In alcuni casi si riesce a recuperare i dati cancellati, in altri le informazioni sono perse per sempre. |
| Gestione dei metadati | Le informazioni vengono solitamente archiviate nei database con i metadati e i metatag. In questo modo si ha più ordine all’interno dei database e si rende possibile ad esempio la funzione di ricerca. Anche i diritti di accesso sono spesso regolati attraverso i metadati. La gestione dei dati segue quattro operazioni fondamentali: create, read/retrieve, update e delete. Questo concetto noto come principio CRUD è alla base della gestione dei dati. |
| Sicurezza dei dati | I database devono essere sicuri, in modo da evitare accessi illegittimi ai dati salvati. Per la sicurezza dei dati sono essenziali sia una gestione attenta, ad opera dell’amministratore responsabile, che un metodo crittografico adeguato. Sicurezza dei dati significa principalmente prendere le dovute precauzioni tecniche per evitare la manipolazione o la perdita di dati. È perciò un concetto base della protezione dei dati. |
| Integrità dei dati | Con integrità dei dati si indica che i dati all’interno di un database contengono regole specifiche, assicurando la correttezza dei dati e definendo la logica aziendale del database. Questo è l’unico modo per garantire che il database nel suo complesso funzioni costantemente in modo coerente. Nei modelli relazionali dei database ci sono quattro regole a riguardo: integrità di settore, integrità dell’entità, integrità referenziale e coerenza logica. |
| Funzionamento multiutente | Le applicazioni del database consentono l’accesso al database da vari dispositivi. Nel funzionamento multiutente, sono fondamentali la distribuzione dei diritti e la sicurezza dei dati. Una delle sfide per i database multiutente riguarda il mantenere i dati coerenti anche con l’accesso in lettura e scrittura di molti utenti senza compromettere le prestazioni. |
| L’ottimizzazione delle query | Da un punto di vista tecnico, un database deve essere in grado di elaborare ogni query in modo ottimale al fine di garantire buone prestazioni: se un database necessita “troppa strada” per elaborare una query di dati, ne risentono le prestazioni complessive del sistema di database. |
| Trigger e stored Procedures | Questi processi sono mini applicazioni salvate all’interno di un sistema di gestione del database, richiamate (triggered) da determinate azioni di modifica. In questo modo tra le altre cose si ottiene un miglioramento dell’integrità dei dati. Per i database relazionali, i trigger di database e le stored procedure sono processi tipici; quest’ultimo può anche contribuire alla sicurezza del sistema se agli utenti è consentito di eseguire azioni utilizzando solo procedure predefinite. |
| Trasparenza di sistema | La trasparenza di sistema è rilevante soprattutto nei sistemi distribuiti: impedendo la distribuzione e l’implementazione dei dati da parte dell’utente, l’utilizzo del database distribuito è simile a quello di uno centralizzato. Diversi livelli di trasparenza del sistema espongono o offuscano i processi in background. La funzione fondamentale, tuttavia, è semplificare il più possibile l’utilizzo. |
Consiglio
Se gestite un database è fondamentale che facciate regolarmente il backup.
Quali modelli di database ci sono?
La differenziazione tra i comuni modelli di database è anche il risultato degli sviluppi tecnici della trasmissione dei dati in forma elettronica. Si trattava soprattutto di efficienza e di usabilità, ma anche di una corsa agli armamenti di noti produttori in concorrenza tra loro.
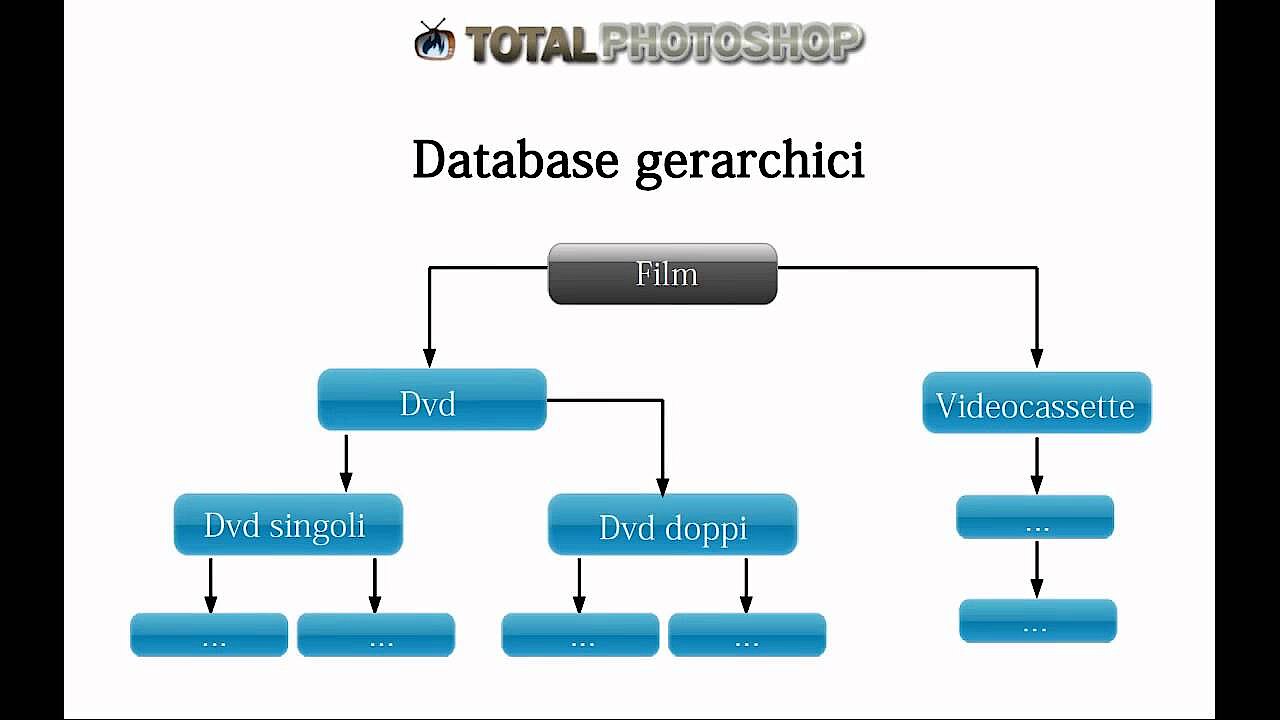
Modello di database gerarchico
Il modello che per primo si è affermato è quello gerarchico, che però nel frattempo è stato ampiamente sostituito dai database relazionali e da altri modelli. Tuttavia recentemente il modello gerarchico è utilizzato abbastanza spesso: XML utilizza questo semplice sistema per l’archiviazione dei dati. Alcune banche e assicurazioni utilizzano ancora database gerarchici, soprattutto quando si usano applicazioni database datate. Il sistema di database gerarchico più conosciuto in assoluto è IMS/DB di IBM.


Nei database gerarchici ci sono dipendenze molto nette. In questo modo ogni record di dati ha un precedente in una relazione “padre-figlio” (parent-child relationship, PCR) ad eccezione del root del database. Ciò porta alla struttura ad albero riportata nella figura sopra. In realtà ogni “figlio” può avere soltanto un “padre”, viceversa ogni “padre” può avere un numero a piacere di “figli”. A causa di questo rigoroso ordine gerarchico, i livelli che non sono direttamente adiacenti non hanno la possibilità di interagire tra loro. Inoltre non si può stabilire facilmente una connessione tra due diversi alberi. Le strutture gerarchiche del database sono perciò estremamente rigide, anche se molto chiare.
I dati che hanno “figli” vengono indicati come “record”, mentre quelli che non ne hanno “fogli”, perché generalmente in un database gerarchico contengono documenti. I record servono principalmente ad ordinare i “fogli”. Ciascuna query rivolta ad un database gerarchico accede in questo modo ad un foglio, raggiunto a partire dal root attraverso i record.
Modelli di database reticolare
Il modello di database reticolare è stato concepito più o meno contemporaneamente ai modelli di database relazionale, anche se sul lungo termine è stato soppiantato dalla concorrenza. A differenza dei modelli gerarchici, qui i dati (record) non hanno una stretta relazione parent-child. Ogni record può avere più antecessori, portando appunto ad una struttura simile ad una rete. Perciò non esiste una via di accesso specifica per un record.


Il record al centro dell’immagine sopra può teoricamente essere raggiunto da cinque altri record. Allo stesso tempo l’accesso al record centrale consente il percorso verso altri cinque record. Nei modelli di database reticolare si possono stabilire delle dipendenze: il record più in alto non dispone di collegamenti immediati con quello all’estrema destra, ma deve passare attraverso quello in mezzo (che può acconsentire o negare l’accesso). Tuttavia può raggiungere direttamente il record in alto a sinistra. In un modello reticolare si possono inserire e rimuovere record in modo fluido senza interferire con la struttura generale.
Oggi il modello di database reticolare è utilizzato soprattutto sui grandi calcolatori. In altri ambiti ci si affida o ancora al modello gerarchico (particolarmente amato dai clienti IBM) o al modello relazionale, più flessibile e semplice da utilizzare. I modelli di database reticolare più noti sono, accanto a USD della Siemens, DMS di Sperry Univac. Entrambi i marchi nel corso degli anni hanno sviluppato forme ibride interessanti che si situano tra il modello reticolare e quello relazionale, senza però riuscire a dare una vera svolta. I risultati di questo tentativo si possono tuttavia vedere ancora oggi in Siemens SQL. Il database grafico, con la sua struttura a rete, è uno sviluppo moderno del modello reticolare.
In questo video potete trovare una breve introduzione ai database e un confronto tra i database gerarchici e quelli reticolari:
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui. Modelli di database relazionale
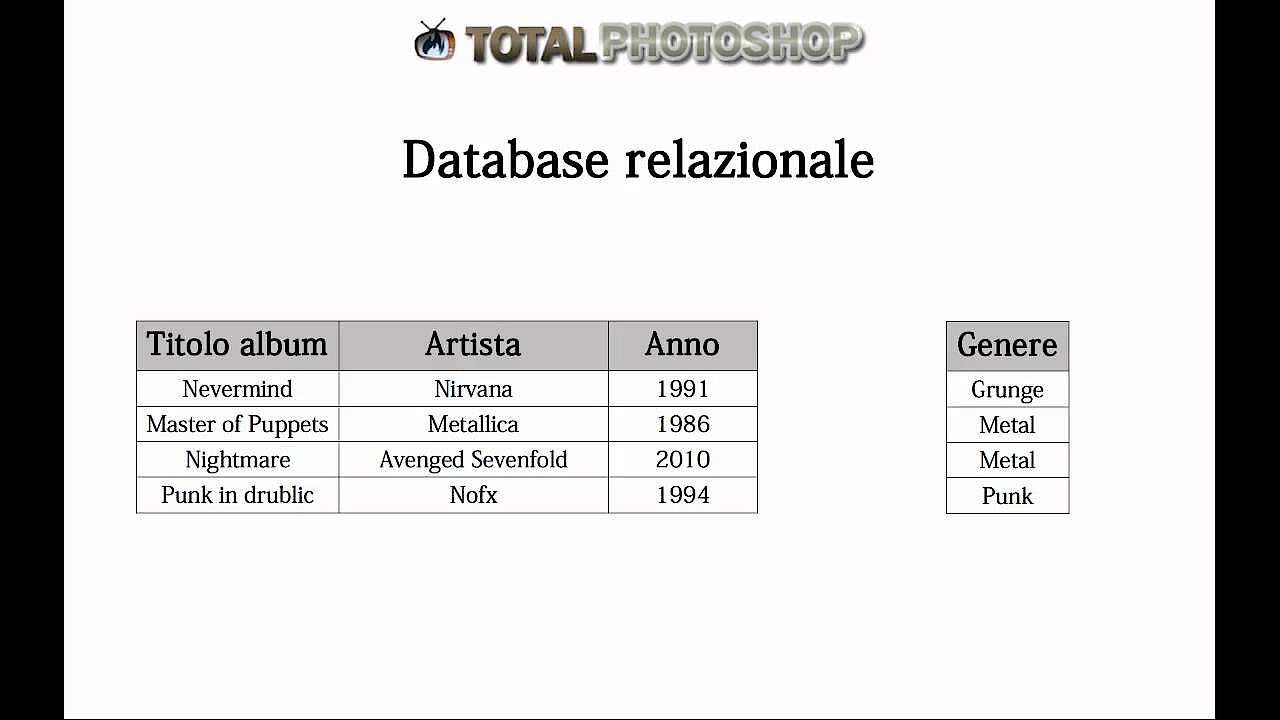
Il modello di database più popolare al momento è quello relazionale, anche se non è esente da critiche. Il relativo sistema di gestione dei database relazionali è meglio conosciuto sotto l’acronimo RDBMS (relational database management system) e il linguaggio più utilizzato è SQL. Il modello di database relazionale basato su tabelle mette appunto al centro il concetto di “relazione”, un concetto matematico ben definito: la formulazione delle relazioni avviene tramite l’algebra relazionale, grazie alla quale si possono ottenere informazioni tramite queste relazioni. Questo principio è a propria volta alla base del linguaggio SQL del database.


Il modello di database relazionale lavora con singole tabelle che stabiliscono la localizzazione delle informazioni e i suoi collegamenti. Queste informazioni vanno a formare un record (nell’immagine sopra una riga, row in inglese, o “tupla”). Le singole informazioni vengono raggruppate nelle colonne come attributi (nella figura A1 fino An). La relazione generale (“relation” è una parola spesso utilizzata come sinonimo di “tabella”) risulta perciò dagli attributi connessi. Per la chiara identificazione di un record è necessario la chiave primaria che generalmente è definita dal primo attributo (A1) e che non può mai cambiare. In altre parole la cosiddetta chiave primaria (anche detta “ID”) definisce la precisa posizione del record con tutti gli attributi.
Nel nostro articolo sui database relazionali, spieghiamo perché si è stabilito questo standard rispetto agli altri, come funziona in dettaglio e quali critiche sono state sollevate in merito al suo utilizzo.
Modello di database a oggetti
I database a oggetto sono stati concepiti per la prima volta alla fine degli anni 80 e ad oggi hanno ancora pochi ambiti di applicazione. Questi database sono a volte disponibili open source e sono utilizzati comunemente su piattaforme Java e .NET. Il database a oggetti più conosciuto è db4o, che garantisce un risparmio in termini di spazio di archiviazione. I database a oggetto lavorano principalmente con il linguaggio OQL, molto simile a SQL.


Nei modelli di database orientati agli oggetti i dati vengono archiviati in un oggetto insieme alle loro funzioni o metodi. Gli oggetti includono anche termini con attributi associati che descrivono il rispettivo oggetto in modo dettagliato. L’accesso a questi oggetti viene definito nel sistema di gestione del database a oggetto utilizzando i “metodi” che sono memorizzati insieme ai dati nell’oggetto.
Gli oggetti inoltre possono essere complessi ed essere costituiti da un numero qualsiasi di tipi di dati. Inoltre gli oggetti all’interno del sistema di database sono unici e sono identificati da un numero univoco (Object ID, OID). Come si può vedere nell’immagine sopra, i singoli oggetti vengono raggruppati in classi di oggetti, configurando una gerarchia di classi. In questo modo il modello parrebbe simile a quello del database gerarchico, ma qui non ci sono delle relazioni fisse sul modello parent-child. Tuttavia attraverso si possono specificare i metodi di accesso utilizzando le classi di oggetti.
I database a oggetto sono vantaggiosi quando si tratta di problemi complessi che coinvolgono la profondità degli oggetti corrispondenti. Normalmente il database a oggetto lavora in modo autonomo senza grandi interventi nella normalizzazione e nella referenziazione degli ID, consentendo quindi un feed-in relativamente semplice e lineare di nuovi oggetti complessi. Le query semplici sono invece molto più veloci in un sistema di database relazionale. La scarsa popolarità dei database orientati agli oggetti porta anche ad una inadeguata compatibilità con molte delle applicazioni comuni per i database.
In questo video potrete vedere un confronto tra i database relazionali e quelli a oggetto:
 Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui.
Per visualizzare questo video, sono necessari i cookie di terze parti. Puoi accedere e modificare le impostazioni dei cookie qui. Modelli di database orientati ai documenti
I documenti costituiscono in questo modello l’unità di base per l’archiviazione dei dati. Essi strutturano i dati e non vanno confusi con i documenti che conosciamo ad esempio dai programmi di modifica del testo. I dati vengono archiviati nelle cosiddette coppie key/value e perciò constano di una “chiave” e di un “valore”. Poiché non è stabilito un numero o una struttura precisa per queste coppie, i documenti singoli all’interno di un database possono apparire molto diversi. Ogni documento è un’unità autonoma. Non è semplice stabilire relazioni tra i documenti, ma in questo modello non sono nemmeno necessarie.
Recentemente i database orientati ai documenti stanno vivendo grazie al successo di NoSQL un vero e proprio boom, specialmente per la loro buona scalabilità. Un esempio di tale sistema è MongoDB.


Nel modello relazionale (rappresentato nella figura con le tabelle) vengono stabilite diverse relazioni per leggere un record di dati comune. Nel modello orientato al documento, è sufficiente un singolo documento per memorizzare tutte le informazioni. Lo schema è inoltre liberamente selezionabile: il modello di database orientato al documento è concettualmente schematico, purché il linguaggio del database utilizzato rimanga lo stesso.
Per i database orientati al documento è fondamentale l’idea che i dati correlati siano sempre memorizzati insieme in un unico luogo (nel documento). Mentre i database relazionali normalmente visualizzano e producono informazioni prevalentemente collegando più tabelle, qui è sufficiente una query indirizzata ad un documento. In questo modo si riduce evidentemente il numero di operazioni necessarie al database.
I sistemi di database orientati ai documenti sono interessanti soprattutto per le applicazioni web, perché possono essere utilizzati per alimentare moduli HTML completi. I database orientati ai documenti sono diventati sempre più popolari soprattutto in seguito allo sviluppo del web 2.0. Tuttavia tra i diversi sistemi di database orientati ai documenti ci sono differenze significative dalla sintassi fino alla struttura interna. Pertanto non tutti i database orientati ai documenti sono adatti per ogni applicazione. Soprattutto a causa di queste diverse interazioni esistono oggi alcuni ben noti sistemi di database orientati ai documenti: Lotus Notes, Amazon SimpleDB, MongoDB, CouchDB, Riak, ThruDB, OrientDB e molti altri.
Modelli di database a confronto
| Modello di database | Periodo di nascita | Vantaggi | Svantaggi | Aree di applicazione | Rappresentanti celebri |
| Gerarchico | Anni 60 | Accesso per la lettura estremamente veloce, struttura chiara, semplice a livello tecnico | Struttura ad albero rigida che non consente collegamenti tra gli alberi | Banche, assicurazioni, sistemi operativi | IMS/DB |
| Reticolare | Inizio anni 70 | Numero maggiore di percorsi per accedere al record, non c’è una rigida gerarchia | Panoramica scarsa per database di grandi dimensioni | Grandi calcolatori | UDS (Siemens), DMS (Sperry Univac) |
| Relazionale | 1970 | Creazione ed elaborazione facile e flessibile, facile espansione, facile da implementare | Ingestibile per grandi quantità di dati, scarsa segmentazione, attributi artificiali delle chiavi, interfaccia di programmazione esterna, raffigurazione carente delle proprietà e comportamento degli oggetti | Controlling, contabilità, sistemi di gestione della merce, sistemi di gestione dei contenuti e molti altri. | MySQL, PostgreSQL, Oracle, SQLite, DB2, Ingres, MariaDB, Microsoft Access |
| Orientato ad oggetti | Fine anni 80 | Migliore supporto di linguaggi di programmazione orientati agli oggetti, memorizzazione di contenuti multimediali | Prestazioni peggiorano all’aumentare dei dati, poche interfacce compatibili | Inventari (musei, vendita al dettaglio) | db4o |
| Orientati ai documenti | Anni 80 | Archiviazione centrale dei dati correlati in documenti singoli, struttura libera, orientamento multimediale | Sforzi organizzativi relativamente elevati, spesso richiedono competenze di programmazione | Applicazioni web, motori di ricerca Internet, database di testo | Lotus Notes, Amazon SimpleDB, MongoDB, CouchDB, Riak, ThruDB, OrientDB |